Note: This tutorial requires Xcode 9 Beta 1 or later, Swift 4 and iOS 11.

Machine learning is all the rage. Many have heard about it, but few know what it is.
This iOS machine learning tutorial will introduce you to Core ML and Vision, two brand-new frameworks introduced in iOS 11.
Specifically, you’ll learn how to use these new APIs with the Places205-GoogLeNet model to classify the scene of an image.
Getting Started
Download the starter project. It already contains a user interface to display an image and let the user pick another image from their photo library. So you can focus on implementing the machine learning and vision aspects of the app.
Build and run your project; you’ll see an image of a city at night, and a button:

Choose another image from the photo library in the Photos app. This starter project’s Info.plist already has a Privacy – Photo Library Usage Description, so you might be prompted to allow usage.
The gap between the image and the button contains a label, where you’ll display the model’s classification of the image’s scene.
iOS Machine Learning
Machine learning is a type of artificial intelligence where computers “learn” without being explicitly programmed. Instead of coding an algorithm, machine learning tools enable computers to develop and refine algorithms, by finding patterns in huge amounts of data.
Deep Learning
Since the 1950s, AI researchers have developed many approaches to machine learning. Apple’s Core ML framework supports neural networks, tree ensembles, support vector machines, generalized linear models, feature engineering and pipeline models. However, neural networks have produced many of the most spectacular recent successes, starting with Google’s 2012 use of YouTube videos to train its AI to recognize cats and people. Only five years later, Google is sponsoring a contest to identify 5000 species of plants and animals. Apps like Siri and Alexa also owe their existence to neural networks.
A neural network tries to model human brain processes with layers of nodes, linked together in different ways. Each additional layer requires a large increase in computing power: Inception v3, an object-recognition model, has 48 layers and approximately 20 million parameters. But the calculations are basically matrix multiplication, which GPUs handle extremely efficiently. The falling cost of GPUs enables people to create multilayer deep neural networks, hence the term deep learning.

A neural network, circa 2016
Neural networks need a large amount of training data, ideally representing the full range of possibilities. The explosion in user-generated data has also contributed to the renaissance of machine learning.
Training the model means supplying the neural network with training data, and letting it calculate a formula for combining the input parameters to produce the output(s). Training happens offline, usually on machines with many GPUs.
To use the model, you give it new inputs, and it calculates outputs: this is called inferencing. Inference still requires a lot of computing, to calculate outputs from new inputs. Doing these calculations on handheld devices is now possible because of frameworks like Metal.
As you’ll see at the end of this tutorial, deep learning is far from perfect. It’s really hard to construct a truly representative set of training data, and it’s all too easy to over-train the model so it gives too much weight to quirky characteristics.
What Does Apple Provide?
Apple introduced NSLinguisticTagger in iOS 5 to analyze natural language. Metal came in iOS 8, providing low-level access to the device’s GPU.
Last year, Apple added Basic Neural Network Subroutines (BNNS) to its Accelerate framework, enabling developers to construct neural networks for inferencing (not training).
And this year, Apple has given you Core ML and Vision!
- Core ML makes it even easier to use trained models in your apps.
- Vision gives you easy access to Apple’s models for detecting faces, face landmarks, text, rectangles, barcodes, and objects.
You can also wrap any image-analysis Core ML model in a Vision model, which is what you’ll do in this tutorial. Because these two frameworks are built on Metal, they run efficiently on the device, so you don’t need to send your users’ data to a server.
Integrating a Core ML Model Into Your App
This tutorial uses the Places205-GoogLeNet model, which you can download from Apple’s Machine Learning page. Scroll down to Working with Models, and download the first one. While you’re there, take note of the other three models, which all detect objects — trees, animals, people, etc. — in an image.
Adding a Model to Your Project
After you download GoogLeNetPlaces.mlmodel, drag it from Finder into the Resources group in your project’s Project Navigator:

Select this file, and wait for a moment. An arrow will appear when Xcode has generated the model class:
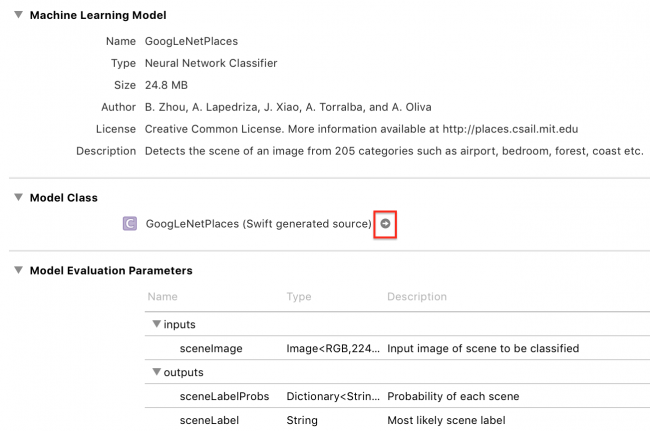
Click the arrow to see the generated class:

Xcode has generated input and output classes, and the main class GoogLeNetPlaces, which has a model property and two prediction methods.
GoogLeNetPlacesInput has a sceneImage property of type CVPixelBuffer. Whazzat!?, we all cry together, but fear not, the Vision framework will take care of converting our familiar image formats into the correct input type. :]
The Vision framework also converts GoogLeNetPlacesOutput properties into its own results type, and manages calls to prediction methods, so out of all this generated code, your code will use only the model property.
Wrapping the Core ML Model in a Vision Model
Finally, you get to write some code! Open ViewController.swift, and import the two frameworks, just below import UIKit:
import CoreML
import Vision
Next, add the following extension below the IBActions extension:
// MARK: - Methods
extension ViewController {
func detectScene(image: CIImage) {
answerLabel.text = "detecting scene..."
// Load the ML model through its generated class
guard let model = try? VNCoreMLModel(for: GoogLeNetPlaces().model) else {
fatalError("can't load Places ML model")
}
}
}
Here’s what you’re doing:
First, you display a message so the user knows something is happening.
The designated initializer of GoogLeNetPlaces throws an error, so you must use try when creating it.
VNCoreMLModel is simply a container for a Core ML model used with Vision requests.
The standard Vision workflow is to create a model, create one or more requests, and then create and run a request handler. You’ve just created the model, so your next step is to create a request.
Add the following lines to the end of detectScene(image:):
// Create a Vision request with completion handler
let request = VNCoreMLRequest(model: model) { [weak self] request, error in
guard let results = request.results as? [VNClassificationObservation],
let topResult = results.first else {
fatalError("unexpected result type from VNCoreMLRequest")
}
// Update UI on main queue
let article = (self?.vowels.contains(topResult.identifier.first!))! ? "an" : "a"
DispatchQueue.main.async { [weak self] in
self?.answerLabel.text = "\(Int(topResult.confidence * 100))% it's \(article) \(topResult.identifier)"
}
}
VNCoreMLRequest is an image analysis request that uses a Core ML model to do the work. Its completion handler receives request and error objects.
You check that request.results is an array of VNClassificationObservation objects, which is what the Vision framework returns when the Core ML model is a classifier, rather than a predictor or image processor. And GoogLeNetPlaces is a classifier, because it predicts only one feature: the image’s scene classification.
A VNClassificationObservation has two properties: identifier — a String — and confidence — a number between 0 and 1 — it’s the probability the classification is correct. When using an object-detection model, you would probably look at only those objects with confidence greater than some threshold, such as 30%.
You then take the first result, which will have the highest confidence value, and set the indefinite article to “a” or “an”, depending on the identifier’s first letter. Finally, you dispatch back to the main queue to update the label. You’ll soon see the classification work happens off the main queue, because it can be slow.
Now, on to the third step: creating and running the request handler.
Add the following lines to the end of detectScene(image:):
// Run the Core ML GoogLeNetPlaces classifier on global dispatch queue
let handler = VNImageRequestHandler(ciImage: image)
DispatchQueue.global(qos: .userInteractive).async {
do {
try handler.perform([request])
} catch {
print(error)
}
}
VNImageRequestHandler is the standard Vision framework request handler; it isn’t specific to Core ML models. You give it the image that came into detectScene(image:) as an argument. And then you run the handler by calling its perform method, passing an array of requests. In this case, you have only one request.
The perform method throws an error, so you wrap it in a try-catch.
Using the Model to Classify Scenes
Whew, that was a lot of code! But now you simply have to call detectScene(image:) in two places.
Add the following lines at the end of viewDidLoad() and at the end of imagePickerController(_:didFinishPickingMediaWithInfo:):
guard let ciImage = CIImage(image: image) else {
fatalError("couldn't convert UIImage to CIImage")
}
detectScene(image: ciImage)
Now build and run. It shouldn’t take long to see a classification:

Well, yes, there are skyscrapers in the image. There’s also a train.
Tap the button, and select the first image in the photo library: a close-up of some sun-dappled leaves:

Hmmm, maybe if you squint, you can imagine Nemo or Dory swimming around? But at least you know the “a” vs. “an” thing works. ;]
A Look at Apple’s Core ML Sample Apps
This tutorial’s project is similar to the sample project for WWDC 2017 Session 506 Vision Framework: Building on Core ML. The Vision + ML Example app uses the MNIST classifier, which recognizes hand-written numerals — useful for automating postal sorting. It also uses the native Vision framework method VNDetectRectanglesRequest, and includes Core Image code to correct the perspective of detected rectangles.
You can also download a different sample project from the Core ML documentation page. Inputs to the MarsHabitatPricePredictor model are just numbers, so the code uses the generated MarsHabitatPricer methods and properties directly, instead of wrapping the model in a Vision model. By changing the parameters one at a time, it’s easy to see the model is simply a linear regression:
137 * solarPanels + 653.50 * greenHouses + 5854 * acres
Where to Go From Here?
You can download the complete project for this tutorial here. If the model shows up as missing, replace it with the one you downloaded.
You’re now well-equipped to integrate an existing model into your app. Here’s some resources that cover this in more detail:
- Apple’s Core ML Framework documentation
- WWDC 2017 Session 703 Introducing Core ML
- WWDC 2017 Session 710 Core ML in depth
From 2016:
- WWDC 2016 Session 605 What’s New in Metal, Part 2: demos show how fast the app does the Inception model classification calculations, thanks to Metal.
- Apple’s Basic Neural Network Subroutines documentation
Thinking about building your own model? I’m afraid that’s way beyond the scope of this tutorial (and my expertise). These resources might help you get started:
- RWDevCon 2017 Session 3 Machine Learning in iOS: Alexis Gallagher does an absolutely brilliant job, guiding you through the process of collecting training data (videos of you smiling or frowning) for a neural network, training it, then inspecting how well (or not) it works. His conclusion: “You can build useful models without being either a mathematician or a giant corporation.”
- Quartz article on Apple’s AI research paper: Dave Gershgorn’s articles on AI are super clear and informative. This article does an excellent job of summarizing Apple’s first AI research paper: the researchers used a neural network trained on real images to refine synthetic images, thus efficiently generating tons of high-quality new training data, free of personal data privacy issues.
Last but not least, I really learned a lot from this concise history of AI from Andreessen Horowitz’s Frank Chen: AI and Deep Learning a16z podcast.
I hope you found this tutorial useful. Feel free to join the discussion below!
The post Core ML and Vision: Machine Learning in iOS 11 Tutorial appeared first on Ray Wenderlich.